
Should I Push or Should I Pull?
The unvarnished truth about speculative push performance
 by Joe Honton
by Joe Honton
In this episode Ernesto decides it's time to put HTTP/2 speculative push to the test. Getting a fully rendered page with just one round-trip request is easy enough to do, but at what cost?
Ernesto is the new guy at Tangled Web Services and he's trying to make a good first impression. He's entered the fray of HTTP/2 performance tuning. After learning the gory details of How Speculative Push with HTTP/2 Really Works, Ernesto decided to put it to the test.
Was it going to be up to all the hype?
Enabling Server Push
First things first. He had to set up his Read Write Serve HTTP/2 server to enable the push-priority module. Here's what he configured:
server {
modules {
push-priority on
cache-control on
etag on
}
response {
push-priority {
push `*.js` *weight=128
push `*.css` *weight=64
push `*.woff2` *weight=32
push `*.jpg` *weight=16
push `*.png` *weight=16
push `*.gif` *weight=16
push `*.svg` *weight=16
push `*.webp` *weight=16
}
}
}
With this set of rules, he was hoping to receive a source document and all of its dependencies in a single HTTP request. And he did. Almost. There were just a couple of things that required tweaking.
The server's automatic preload detection (APD) algorithm correctly discovered and pushed scripts, style sheets, and almost all of the images. But APD only parses and discovers resources that are directly referenced in the source document. The background images specified in his CSS were indirectly referenced, so were not discovered. Also, the web fonts that he specified in @font-face rules were missed for the same reason. But both of these indirect references could be made explicit easily enough by inserting preload statements in the document's head. Those tweaks looked something like this:
<link href='image/hero.png' rel='preload' as='image' />
<link href='fonts/neue.woff2' rel='preload' as='font' crossorigin />
With those in place, he was able to achieve his goal: a fully rendered page with just one round-trip from the browser to the server!
He monitored the server's log to see how it happened. The log's RR entry is the request/response identifier. The first request is RR=0, requesting the path PA=/ (the website's default index page). The next twelve requests are speculative push requests initiated and fulfilled by the server over push streams RR=0-0 through RR=0-11. They are the document dependencies discovered by the server and speculatively pushed to the browser.
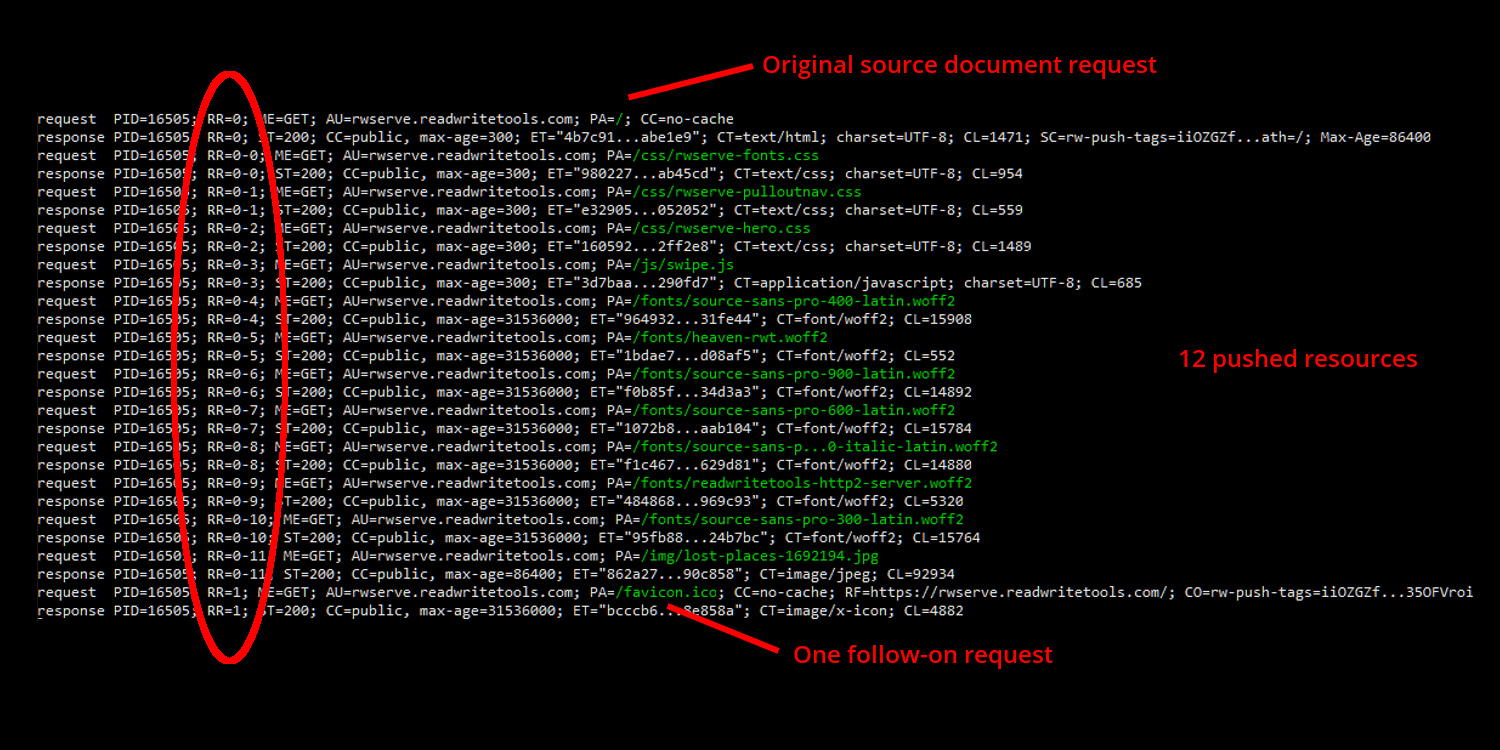
One follow-on request RR=1 was initiated independently by the browser for the website's PA=/favicon.ico. The current release of Chrome (version 74) requests this file for every document, which Ernesto thought was overzealous, especially since his server explicitly set the cache-control to expire with a max-age of 365 days. He filed a bug report, and for the remainder of his work ignored it.
Ernesto turned his attention to the client side. He opened Chrome's inspector and examined the network tab. The Initiator column contained the entry "Push/(index)" for the twelve resources pushed by the browser. He was satisfied that both server and client were doing their parts as advertised.
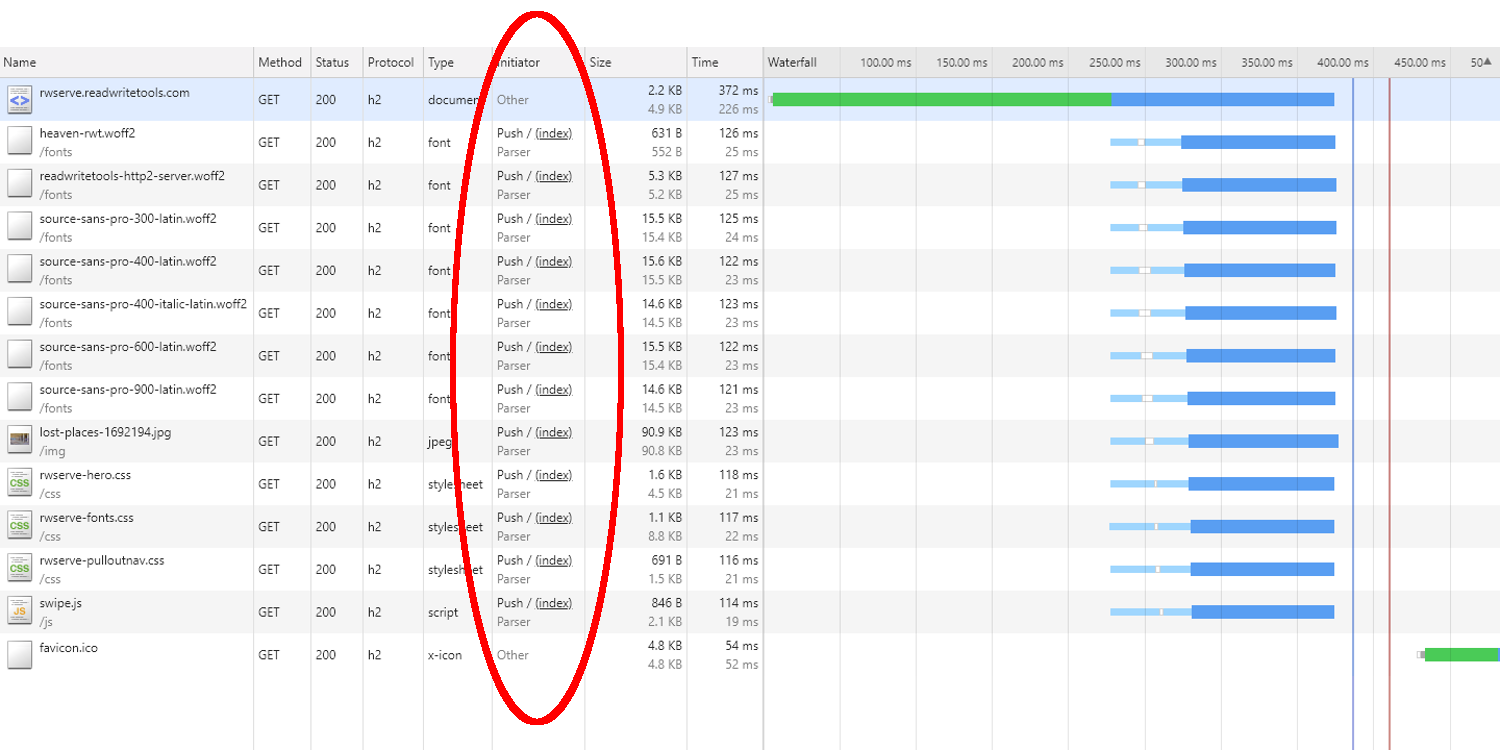
Ernesto was thrilled to see how easy it was to enable speculative push for his websites. He went through all of his virtual servers and changed their configuration files to match what he'd just tested. In just under an hour he had 41 websites using speculative push in production.
Comparing Push to Pull
In order to measure the difference between push and pull, Ernesto cloned several different websites onto a stand-alone server and configured them to be accessible through DNS and the public Internet. He wanted real world results using the domain name resolver, TLS certificate handshakes, cold sessions, and cookie exchange. But of course he also wanted to isolate network, CPU, and memory overhead so that he could properly measure response times without noise.
He performed a series of test cases with push enabled and disabled. Each test case consisted of five separate test runs, where the measurements were averaged and used for comparison. He set his session timeout to 5 seconds, so that each test run would be coming in cold.
For each test run he captured the amount of time for DNS name resolution, TLS handshake, server processing, and network transmission. The first two are clearly reported by the Chrome inspector in the network tab. The time to first byte (TTFB) was taken to be the "server processing time". And the network transmission time was computed backwards by subtracting those three from the time for the page to be fully loaded.
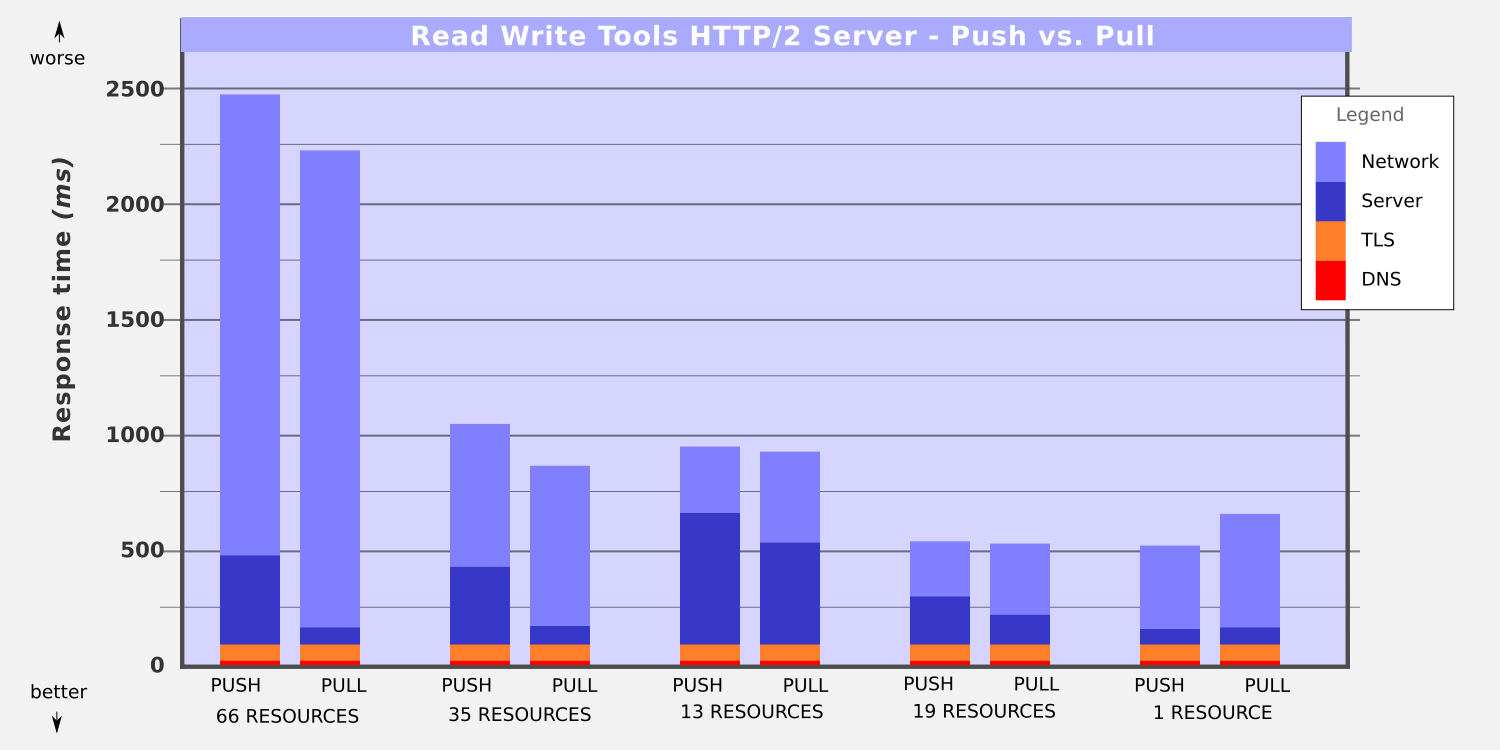
The first test case pair had 66 resource files (4 css, 1 script, 10 fonts, 51 images). Pushing those resources consumed slightly less network time, 1995 ms versus 2079 ms. But the server overhead of determining what to push and setting up the push streams was much greater. The final result: pushing resulted in a 234 ms penalty.
The next test case pair had 35 resource files (4 css, 1 script, 10 fonts, 20 images), and a similar result profile. Pushing consumed less network time, 606 ms versus 686 ms, but server overhead was again much greater. The final result: pushing resulted in a 161 ms penalty.
The third test case pair had 13 resource files (3 css, 1 script, 8 fonts, 1 image). The results were much closer, both in server processing disparity, and in overall response time. The server overhead for push was 567 ms versus 434 ms. And again pushing consumed less network time, 250 ms versus 345 ms. The final result was nearly a tie: pushing resulted in a slight 35 ms penalty.
The fourth test case had 19 resource files (3 css, 1 script, 13 fonts, 2 images). The results were a tie. The server overhead for push was 212 ms versus 116 ms. And again pushing consumed less network time, 244 ms versus 331 ms. Pushing resulted in an insignificant 9 ms penalty.
The fifth and final test case had just 1 resource file (a large image). This is the only case where pushing resulted in a better overall page response time. The server overhead for push was 52 ms while the server overhead for pull was 56 ms. But the network time for push was clearly better, 443 ms versus 574 ms. Pushing resulted in a 138 ms improvement.
The third and fourth test cases were indicative of the tug-of-war between push and pull. Pushing takes extra time on the server side to determine what to push and to set up the streams. Pulling takes extra time on the browser side to determine what to pull and to set up the streams.
The next morning at scrum Ernesto reported, "It's difficult to draw conclusions about how to design a generic push strategy. Should the formula be based on number of resources, or file size, or file type?
"Your mileage may vary sounds like a cop-out, but it's true," he added. "One thing's for sure, blindly adding push to everything is probably not going to improve things in most cases, but probably won't hinder things a lot either. The smartest thing to do is put it to the test yourself."
"Like I said . . . dragons," Ken blurted out.
"I don't know what you mean," Ernesto said, "Dragons?"
"It's a reference to uncharted territory, meaning, nobody knows what you'll find there," Ken explained.
"Wait, not so fast . . . technically it's no longer uncharted anymore, since I've just created a chart for it," Ernesto grinned. "It may be crude, but it's a beginning."
"OK, fair enough," Ken said. "By the way, others have come to similar conclusions.
"The hype around speculative push has set expectations too high. The real champs of HTTP/2 are multiplexed streams and persistent sessions. Together those two make it possible for the browser to request and receive content for everything it needs much faster than HTTP/1.1.
"Think about it, a stream is a stream, it doesn't make much difference who initiated things. The number of bytes transmitted is identical. And the overhead of a DNS lookup and a TLS handshake only happen once per page, regardless.
"In some way it makes sense that pull is faster than push because there's only one party to the conversation deciding what's needed and only one party issuing orders. When the server stops pretending to be smart, and starts letting the browser be the one source of truth, it probably saves some duplicate processing effort.
"I'm just sharing a gut feeling here, without empirical measurements," Ken finished, "so take it with a grain of salt."
"Well, I'll concede that there's no easy answer here," said Ernesto, "but I'm not giving up so easily."
"Dragons!" said Ken.
"No," said Ernesto, desperate for the last word, "Charts!"
Ernesto wasn't sure if he had gained the respect of his new work mates. Maybe he picked the wrong path for demonstrating his technical chops. Still, he had learned a lot about HTTP/2 performance.
No minifig characters were harmed in the production of this Tangled Web Services episode.
Follow the adventures of Antoní, Bjørne, Clarissa, Devin, Ernesto, Ivana, Ken and the gang as Tangled Web Services boldly goes where tech has gone before.



