
Lessons Learned from Stress Testing Node.js
How to match cluster size to number of CPU cores
 by Joe Honton
by Joe Honton
In this episode Devin and Ken battle it out in competing benchmark tests. Their goal: finding a golden rule for configuring Node.js cluster size.
Tangled Web Services was getting rowdy. Devin and Ken were posturing with all the bravado and tech savvy of two alpha males.
"There's no way that can be right," declared Devin, "matching server cluster size to the number of hardware CPUs is just brain-dead!"
"No it's not," shot back Ken, "it makes perfect sense to me."
"How can you say that? OS kernels handle hundreds of system threads at the same time with fast context switching," Devin argued. "With pipelining cores, one thread can be sitting on the sidelines waiting for a disk I/O operation to complete. Another thread can be waiting for the network interface card to stream remote bytes. A third thread might have off-loaded a math calculation to the math processor."
"It seems to me," Devin concluded, "that a single web server might be able to use as much as a 4:1 ratio of worker threads to CPUs."
"It seems to me," Ken chided him, "you'd be wrong."
Devin had a sound argument, you couldn't fault his technical chops. But Ken had been to enough rodeos to know that the 1:1 guideline always seemed to be right.
"All the docs say that you should match the Node.js cluster size to the number of CPUs," Ken went on. "Who are we to say otherwise? Of course the real way to settle this is to put it to the test."
"OK," Devin took the bait, "I'm in."
"Fine. Set it up and prove it to me." That was Ken's final word on the matter. But privately, he figured Devin would just drop the whole thing. Benchmarking is a lot of work.
Devin wasn't going to let it go. He dived right in.
His websites were hosted using Read Write Tools HTTP/2 Server, which uses Node.js clustering. It's fully capable of handling up to 64 clustered worker threads.
For his test harness, Devin downloaded and compiled the h2load stress testing tool, version 1.39.0-DEV. He set up his test harness on a Digital Ocean droplet running 64-bit Debian 9.5.
On the server side, he decided to use every type of Digital Ocean droplet that fit his budget, from a $5/month 1CPU/1GB droplet to a $160/month 8CPU/32GB droplet. He configured a standard image with 64-bit Fedora 29. The only service he installed was the Read Write Tools HTTP/2 Server, version 1.0.26. That server requires HTTPS, so he grabbed a free LetsEncrypt cert for his test domain, and configured it to use TLS with ECDHE-RSA-AES128-GCM-SHA256.
As a standard test suite, he wanted to simulate more than just "Hello World", so he chose three files of graduated size: a 1K file, a 32K file, and a 1024K file. Using three separate test runs, these would be requested repeatedly by the stress tester for a set duration. Each test run would simulate 20 concurrent inbound clients.
Devin began executing the test runs on the smallest droplet. He started with a server cluster size of 2, then increased it geometrically to 4, 8, 16, 32 and 64. Each droplet was the target of 18 test runs (3 file sizes * 6 cluster sizes) forming a test series.
He spun up and ran the test series on 12 different-sized droplets — 9 "Standard" plans, 1 "General Purpose" plan, and 2 "CPU Optimized" plans. In total, he executed 216 test runs.
For each test run he captured memory usage, requests per second (req/sec), and bytes transferred over the network. He plotted the results.
He was disappointed.
Scheiße! Ken was probably right.
The 1CPU and 2CPU droplets did best with 2 clusters. The 3CPU and 4CPU droplets did best with 4 clusters. The 6CPU and 8CPU droplets did best with 8 clusters. All of them fared poorly when configured using 16, 32 or 64 clusters.
The next morning Devin shared his findings.
Ken was surprised that Devin had put so much effort into it. He decided to be gracious in victory. "Great work, by the way. I'm impressed."
"Yeah, it's looking like I was wrong, but I'm just not sure why," he began, then shared a few of the things he learned. "The Standard plans worked best. The General Purpose and CPU Optimized plans didn't fare better at all — they cost more and delivered less. I guess they're geared towards databases and number crunching, not websites.
"Network latency was negligible. Since the client and server were both in the same data center, there was no transmission delay. I used traceroute, and could see that there were only two hops with less than one millisecond total delay. Still I noticed that all of the 1 megabyte files were capping out at 234 req/sec (234 MB/sec), regardless of cluster size, memory or CPU count. I figured that was due to the NICs. A single 2Gbps NIC is theoretically capable of 250MBps, so I guess it makes sense.
"The smaller droplets were memory constrained. The HTTP/2 Server's master thread needed 694MB memory, and each worker thread needed 605MB memory. The 1GB droplets completely failed when trying to test more than 16 clusters. The OS virtual memory pager thrashed itself to death.
Devin finished up, "If I could do it all over, I'd do it differently."
Ken's interest was piqued.
The next day Ken snuck a copy of the droplet image used by Devin, and logged into the client machine with the h2load stress tester.
After a bit of playing around, Ken came up with a new series of tests. He used the same configuration, same versions, same HTTPS cipher suite, same number of concurrent clients. But he used just the first two test files. He discarded the 1024K file — clearly it was skewing the results. And instead of changing the cluster size geometrically, he changed it linearly. He decided each series would consist of 1, 2, 3, 4, 5, 6, 7, 8 and 16 clusters. That way he could see things in finer detail. Finally, he dropped two of the 1CPU plans because they were redundant, and added one high-end plan, a pain point at $240/month — the 12CPU/48GB monster server.
He plotted his results, circling the optimal cluster size in each series.
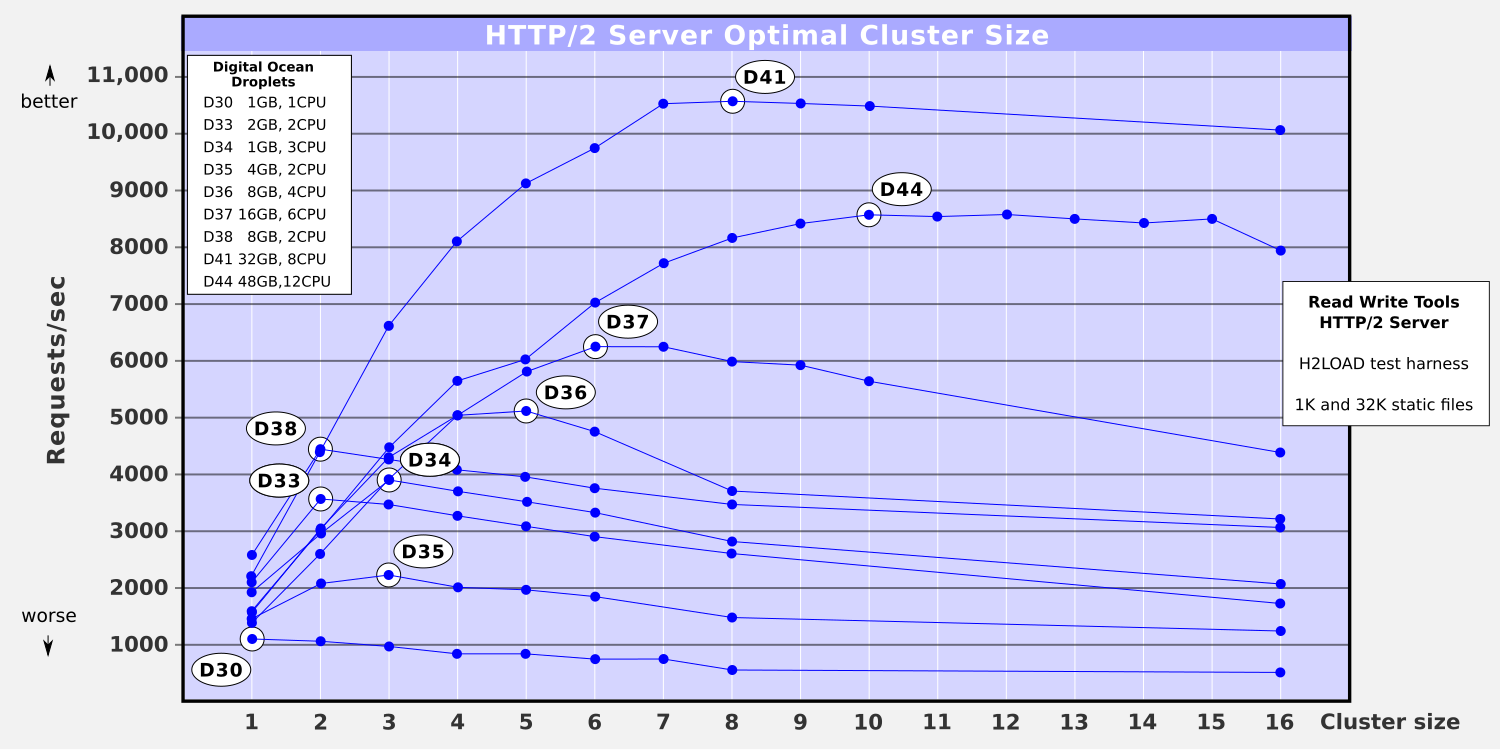
He was pleased with the clarity visible in the results. He drew up a summary table and sent it to Devin.
HTTP/2 Server Optimal Cluster Size by Droplet Type
Optimal
Droplet | RAM | CPUs | Cluster size
--------|-------|--------|-------------
D30 | 1GB | 1CPU | 1
D33 | 2GB | 2CPU | 2
D34 | 1GB | 3CPU | 3
D35 | 4GB | 2CPU | 3
D36 | 8GB | 4CPU | 5
D37 | 16GB | 6CPU | 6
D38 | 8GB | 2CPU | 2
D41 | 32GB | 8CPU | 8
D44 | 48GB | 12CPU | 10
"Hey Devin, looks like my results and your results pretty much match up. The impact of cluster size on overall throughput is clearly visible. Both too few, and too many, really impact throughput.
"When I studied the details, I could see that memory swapping was a consideration, but not nearly as much as CPU count.
"Also, even though I discarded the 1024K file from the test suite, I still ran into the network throttle on droplets D41 and D44. D41 went off the chart at 13,609 req/sec for the small 1K file by itself. Unfortunately, the 32K file brought the average way down, skewing the plot badly for cluster sizes 4 through 16. And D44 was skewed downward too, for cluster sizes 7 through 16.

"Incidentally the monster 48GB/12CPU, at $240/month, never came close to matching the cheaper 32GB/8CPU droplet — it's a clear all-around winner.
"I think the final take-away is that optimal cluster size is equal to number of CPUs, as I originally argued. But the mechanics are more complicated than that golden rule reveals."
Devin thought about it for a while and couldn't argue back, so instead of conceding, he simply replied, "You may be right, but of course your mileage may vary."
Tangled Web Services quieted down after the alpha males stopped growling, and everyone hunkered down for the rest of the day with their headsets on.
No minifig characters were harmed in the production of this Tangled Web Services episode.
Follow the adventures of Antoní, Bjørne, Clarissa, Devin, Ernesto, Ivana, Ken and the gang as Tangled Web Services boldly goes where tech has gone before.



