
Why Compressing Small Files is a Bad Idea
Coming to grips with the GZIP penalty
 by Joe Honton
by Joe Honton
In this episode Ken discovers a ghost in the machine when comparing GZIP requests-per-second and GZIP bytes-transferred.
Ken is the resident tech guru at Tangled Web Services. He's the "go to" guy for all the hard stuff.
Ken wanted to know how much boost his server was getting by turning on compression. Surely it was a no-brainer that compression should be enabled and used whenever possible. Even if it was purely for the boasting rights, he thought it would be useful to actually measure it.
But instead of the big boost he was expecting, he discovered a ghost in the machine.
The encoding protocol
Just to be on the safe side Ken reviewed his understanding of how the HTTP in-transit compression protocol works. It goes like this:
A user-agent that can handle compression sends an accept-encoding header along with its request. That header lists its compression preferences. Most browsers prefer GZIP, but will handle DEFLATE if necessary. Newer browser versions (since 2106), also handle BROTLI compression.
When the server receives a request with an accept-encoding header, it examines the requested preferences and chooses the first one that it can handle. Upon return, it sends a content-encoding response header, specifying which compression type it chose.
Configuring the server
Not every request should be compressed.
Some file types are already compressed by their very nature. Binary media, including images, audio, and video, are already compressed using their own algorithms, and attempting to compress them further with gzip or deflate provides very little improvement, and in some cases actually increases file size. (Note that SVG images are actually text files, so they do benefit from compression.)
Font files are a mixed bag. The older file formats ttf and otf should be compressed, but the newer woff2 file format should not.
Compression is most useful on text files such as html, css and js.
Ken configured his server like this:
content-encoding {
text/css gzip
text/html gzip
text/plain gzip
application/javascript gzip
application/json gzip
application/pdf none
application/xhtml+xml gzip
application/xml gzip
application/gzip none
image/gif none
image/jpeg none
image/png none
image/svg+xml gzip
image/webp none
image/x-icon none
audio/mpeg none
video/mp4 none
audio/webm none
video/webm none
font/otf gzip
font/ttf gzip
font/woff2 none
}
The test harness
Ken set up his test harness using two Digital Ocean droplets. One was the simulated test client, running the h2load stress testing utility. The other was the simulated test server, running the HTTP/2 Server.
The simulated test client was setup like this:
- Intel 1.8GHz CPU
- 1 GB RAM
- 1 Gpbs network interface
- 64-bit Debian 9.5
h2loadsoftware nghttp2/1.39.0-DEV
The simulated test server was setup like this:
- Intel 1.8GHz CPU
- 1 GB RAM
- 1 Gpbs network interface
- 64-bit Fedora 29
- Read Write Tools HTTP/2 Server 1.0.26
- Node.js 10.13.0
Test suite and results
The server test suite consisted of eleven text files, sized from 1KB to 1MB.
A series of stress tests were conducted, each lasting for 20 seconds, and each comprising 20 simulated clients repeatedly requesting one of the text files. Two results were recorded: how many requests were made, and how much data was transferred.
The same series of tests were conducted twice: once with no compression and once with gzip compression.
Here are the results:
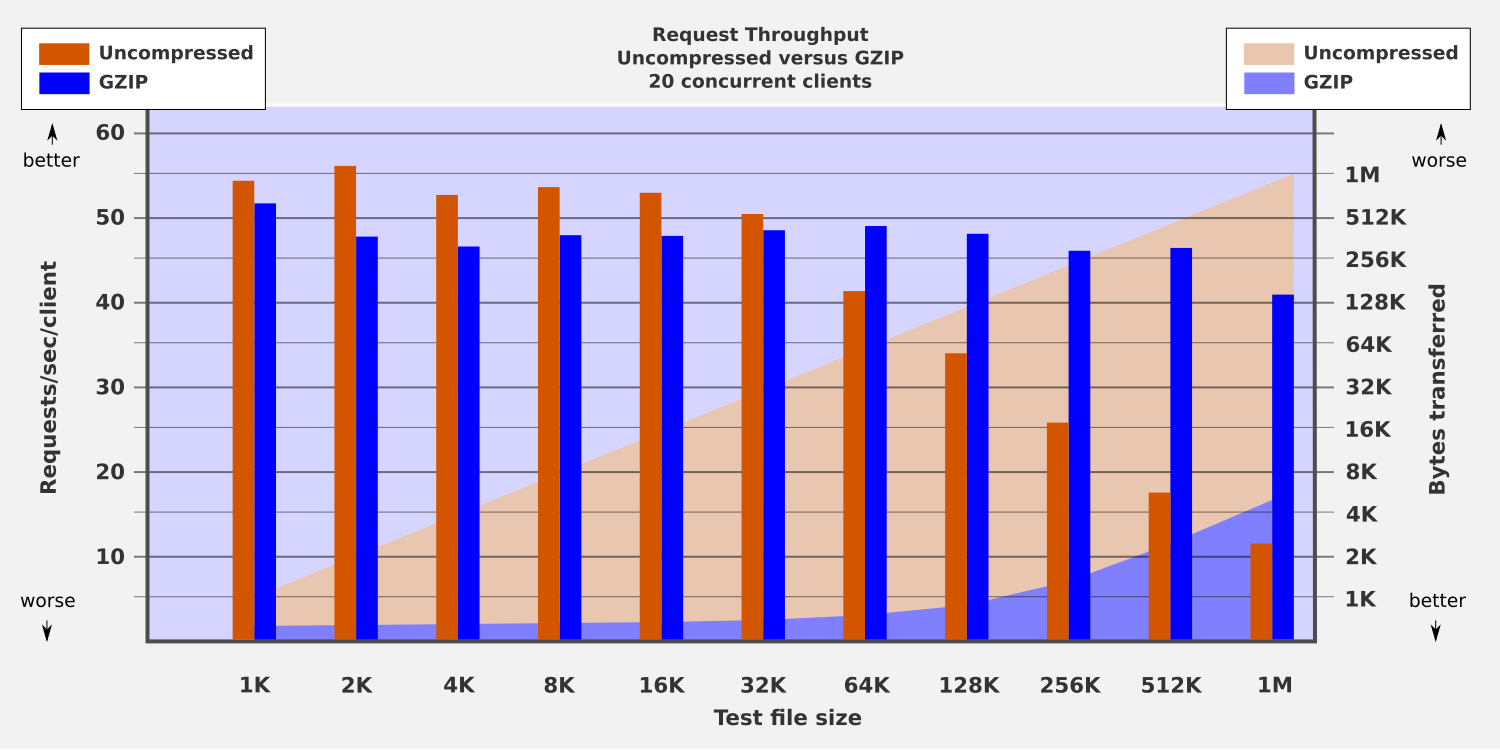
What just happened
Ken studied the chart.
- Requests per second per client are shown with vertical bars using the scale on the left-hand y-axis.
- Bytes transferred are shown with shaded background colors using the scale on the right-hand axis.
First, the uncompressed requests, which are shown in orange.
Smaller files have the best results, somewhere between 51 to 56 req/sec/client. Larger files — beginning with the ones sized 64K — have worse results, tapering from 41 to 12 req/sec/client.
The overall downward trend was predictable. As more bytes are sent down the wire, fewer requests can be handled in the same amount of time. The orange-shaded background confirms this by showing the bytes transferred. It increases linearly from 1KB on the bottom left to 1MB on the top right.
Now, the gzip requests, which are shown in blue. The blue vertical bars are similar across all tests, ranging from 52 to 41 req/sec/client.
"That's cool," thought Ken. "Even though I'm sending much larger files, I'm still getting excellent throughput."
The shaded blue background provides ample confirmation that gzip compression is working. For this contrived test suite, smaller files have compression ratios between 1:2 and 1:64. Larger files have compression ratios as high as 1:200. From the user's perspective, both small files and large files take about the same amount of time.
Nobody was complaining about that.
The surprise factor
The overall trends for uncompressed versus gzip met Ken's expectations. But there was something odd about the orange vertical bars for the smaller files (the ones in the 1K to 32K range).
Uncompressed requests have better throughput than gzip requests!
"What gives?" Ken was puzzled. "Maybe it's the time it takes for the server to compress the file?"
Nope. The Read Write Tools HTTP/2 Server caches gzip files after the first request, and uses the cached version for all later requests.
"Maybe it's the time it takes for the browser to decompress the file?" Ken thought.
Nope. The h2load test software only measures the round-trip request/response cycle. It doesn't take the extra step of actually decompressing the payload.
Ken was starting to grasp at straws. "Maybe it's network-related?"
Almost certainly not. Both the simulated test client and the simulated test server are in the same Digital Ocean data center. Even though they are using the public Internet, with the full network stack, there is almost no network latency. Ken had already gone down that road with some of his other benchmark tests. A traceroute command was able to reach the server in just two hops, with less than 1 ms delay.

It was time for a Level 3 tech support request.
Ken slacked his friend Ping.
"Do you realize what time it is over here?" Ping replied.
"Uh, sure. But you work in the middle of the night anyway, right?" Ken replied. "Besides, I need your help. Take a look at these benchmarks. Got any clues?"
Silence.
20 Minutes Later
"OK, it's MTU," declared Ping, with his typically terse manner.
Now even for Ken that required a bit of interpretation. Here's the translation:
Data transmission through the TCP/IP stack is governed by the Ethernet Maximum Transmission Unit (MTU). It's a fixed size. On most Ethernet NICs it is 1500 bytes. Responses where the HTTP headers plus payload is less than the MTU, all pay the same network cost.
Of course the size of response headers varies, but with HTTP/2 HPACK header compression it can be relatively small, say 100 bytes. The RWSERVE HTTP/2 Server is smart enough to not even try gzip or deflate compression on files smaller than 1400 bytes.
The test suite files in question were sized 1K through 32K. Obviously the 1K file would never be compressed under these rules, but all the others would be.
But as it turns out, the compression ratio for those files was so great that they compressed down to a size less than 1400 bytes. The shaded blue background on the chart shows this. As a result, they were each subject to the same MTU threshold.
The throughput penalty for the gzip versus uncompressed files was somewhere around 2 ms per request — the time it took for the server to go down the "send me the cached copy" logic path.
So in the end, in terms of network bandwidth cost, the gzip files were clearly a winning proposition. But in terms of network latency, small gzip files had a slight disadvantage over their uncompressed source.
Ken knew that it was all much ado about nothing. Still, he took a certain pride in learning something new. Maybe it was time to add NetOps to his title. Nah!
No minifig characters were harmed in the production of this Tangled Web Services episode.
Follow the adventures of Antoní, Bjørne, Clarissa, Devin, Ernesto, Ivana, Ken and the gang as Tangled Web Services boldly goes where tech has gone before.



